 是我们生活中语言是传递信息最重要的方式,它在人们之间是相互理解的。 人与机器的互动也是同样的理由,让机器人知道人在做什么,在做什么。 交互方式有动作、文本、语音等,其中语音交互越来越受到重视。 随着互联网上智能硬件的普及,产生了各种互联网入口方式,语音是最简单直接的交互方式,是最通用的输入方式。
是我们生活中语言是传递信息最重要的方式,它在人们之间是相互理解的。 人与机器的互动也是同样的理由,让机器人知道人在做什么,在做什么。 交互方式有动作、文本、语音等,其中语音交互越来越受到重视。 随着互联网上智能硬件的普及,产生了各种互联网入口方式,语音是最简单直接的交互方式,是最通用的输入方式。
1952年,贝尔研究所开发出了世界上第一个能识别10个英语数字发音的系统。 1960年英国的Denes等人开发了世界上第一个语音识别( ASR )系统。 大规模语音识别研究始于70年代,单词识别取得了实质进展。 20世纪80年代以后,语音识别研究的重点转向了更普遍的大词汇、非特定人的连续语音识别。
90年代以来,语音识别的研究进展不大。 但语音识别技术的应用和产品化取得了重大进展。 自2009年以来,随着深入学习研究的突破和大量语音数据的积累,语音识别技术得到了飞跃发展。
深度学习研究采用预训多层神经网络,提高了声学模型的精度。 微软研究人员首次取得突破性进展,他们使用深层神经网络模型后,语音识别错误率减少了三分之一,近20年来在语音识别技术方面取得了最快进展。
另外,随着手机等移动终端的普及,大量的文本数据和声音数据被存储在多个信道中,这提供了模型训练的基础,使通用的大规模语言模型和声音模型的构筑成为可能。 在语音识别中,丰富的样本数据是快速提高系统性能的重要前提,但词汇表述需要长期积累和沉淀,大规模词汇资源积累需要提高到战略高度。
现在,语音识别是移动终端和扬声器的应用最热烈,语音聊天机器人和语音助理等软件陆续登场。 很多人第一次接触语音识别,也许是多亏了苹果手机的语音助手Siri。
Siri技术来源于美国国防部高级研究计划局( DARPA )的CALO计划:军队是一个简单处理复杂事务、具有认知能力学习、组织的数字助理,民间版是Siri虚拟个人助理。
Siri公司成立于2007年,最初以文字聊天服务为主,之后与着名语音识别厂商Nuance合作实现了语音识别功能。 2010年,Siri被苹果收购了。 苹果在2011年和iPhone 4S一起推出了这项技术,之后Siri的功能继续提高。 现在,Siri成为苹果iPhone上的语音控制功能,可以使手机变成智能的机器人。 通过自然语言的语音输入,可以调用天气预报、地图导航、资料检索等各种APP,通过持续学习改善性能,提供交互式响应服务。
语音识别( ASR )原理
语音识别技术是通过机器的识别将语音信号转换成文本,并且进一步通过理解将语音信号转换成指令的技术。 目的是赋予机器人的听觉特性,理解人在说什么,并采取相应的行动。 语音识别系统通常由声学识别模型和语言理解模型两部分组成,支持从语音到音节、从音节到单词的计算。 一个连续语音识别系统(以下图)由特征提取、声学模型、语言模型、解码器等4个主要部分构成。
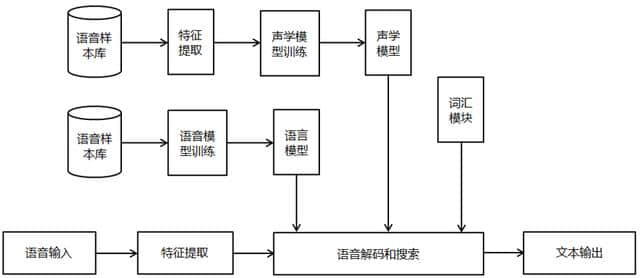 (1)声音输入的预处理模块
(1)声音输入的预处理模块
处理输入的原始声音信号,其中不重要的信息和背景噪声被滤波,诸如声音信号的端点检测(即,找到声音信号的结束点)、声音片段(其可以近似为由多个帧的有序屏幕组成,例如声音或视频,并且可以将声音信号切割成单个“屏幕”进行分析)等
(2)特征提取
在声音信号中除去语音识别中不需要的冗馀的信息后,保留能够反映声音的本质特征的信息,进行处理,用一定的形式表现。 即,提取反映声音信号的特征的关键特征参数来形成特征向量序列,用于后续处理。
(3)声学模型的训练
声学模型可以理解为对声音建模的、将声音输入转换为声学表示的输出,并且准确地说,给出声音属于某个声学符号的概率。 基于训练语音库特征参数训练语音学模型参数。 识别时,将应识别的语音特征参数与声学模型相匹配,可以得到识别结果。 现在主流的语音识别系统多采用隐马尔可夫模型HMM对音响模型进行模型化。
(4)语言模型训练
语言模型是用于计算句子出现概率的模型,简单来说就是计算句子在语法上是否正确的概率。 句子的构造多是有规律的,所以前面出现的词常常预言后面出现的可能性。 这主要用于预测决定哪个词序的可能性高,或者在出现几个词时下一个出现的词。 这可以定义哪个单词跟在当前识别的单词之后(匹配是顺序的处理过程),并排除在匹配过程中不可能出现的单词。
语言建模能有效结合汉语语法和语义知识,描述词语之间的内在关系,提高识别率,减少搜索范围。 对训练文本数据库进行语法、语义分析,通过基于统计模型的训练得到语言模型。
(5)语音译码和搜索算法
解码器是语音技术中的识别过程。 对于输入的语音信号,基于自己训练的HMM声学模型、语言模型、词典构建识别网络,基于搜索算法在该网络中寻找最佳路径。 该路径以能够以最大概率输出该声音信号的单词串来确定该声音样本中包括的字符。 因此,解码操作是指在解码侧通过搜索技术来搜索最佳单词串的搜索算法。
连续语音识别中的搜索通过搜索描述输入语音信号的单词模型序列,得到单词解码序列。 检索基于公式声学模型评分和语言模型评分。 在实际使用中,经常根据经验对语言模型加以高度加权,设定长语言的惩罚分数。
语音识别本质上是模式识别的过程,将未知语音的模式与已知语音的参照模式逐一进行比较,以最佳匹配的参照模式作为识别结果。 当今语音识别技术的主流算法是基于动态时间规则( DTW )算法、基于非参数模型的向量量化( VQ )方法、基于参数模型的隐马尔可夫模型( HMM )方法、以及近年来的深度学习和支持向量机等的语音识别方法。
站在巨人肩膀上:开源框架
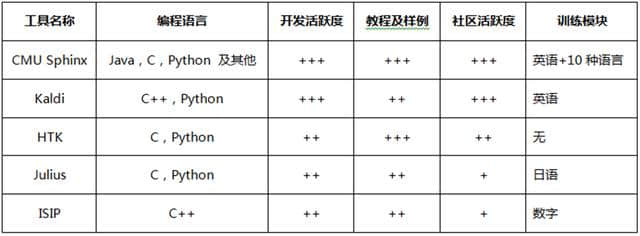
目前,开源世界提供了多种不同的语音识别工具包,为开发人员构建应用程序提供了很大帮助。 但是,这些工具各有优劣,有必要根据情况选择使用。 下表是目前比较流行的工具箱之间的比较,以传统的HMM和N-Gram语言模型为基础的开源工具包比较多。
 对于普通用户来说,知道Siri和Cortana这样的产品的人很多。 对于研发工程师来说,更灵活、集中的解决方案更符合他们的需求,许多公司开发自己的语音识别工具。
对于普通用户来说,知道Siri和Cortana这样的产品的人很多。 对于研发工程师来说,更灵活、集中的解决方案更符合他们的需求,许多公司开发自己的语音识别工具。
(1)CMU Sphinix是卡内基梅隆大学的研究成果。 已有20年的历史,Github和SourceForge已经开源,两个平台都有很高的成活度。
(2)Kaldi从2009年的研讨会开始就有学术基础,现在在GitHub开源,开发成活度很高。
(3)HTK在剑桥大学开始,长期以来是商用的,但着作权已经不再是开源。 最新版本已于2015年12月更新。
(4)Julius始于1997年,最后一个主要版本于2016年9月发布,主要支持日语。
(5)ISIP是产生于密西西比州立大学的最新型开源语音识别系统。 主要发展于1996年至1999年,最终版发表于2011年。 不幸的是,这个项目已经不存在了。
语音识别技术研究难点
目前语音识别研究进展缓慢,困难具体表现如下
(1)输入不能标准统一
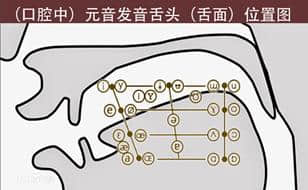
例如,各地方言的不同,每个人的发音习惯等,如下图所示,口腔内的母音根据舌头的部位可以发出各种各样的声音,组合变化激烈的辅音,会产生很多类似的发音,挑战语音识别。 除去口音的偏差,如果输入机器不统一的话,声音输入的基准就会偏离。
 (2)噪音烦恼
(2)噪音烦恼
噪声环境的各声源处理是目前公认的技术课题,机器不能从各级背景噪声中辨别人声,而且背景噪声千差万别,训练情况也不完全符合现实环境。 因此,语音识别在噪音中在安静的环境下更加困难。
当前主流的技术思路是通过改进算法来减少误差。 首先,从收集到的原始声音中,提取抗噪声性高的声音特征。 并在模型训练时结合噪声处理算法训练语音模型,提高了模型在噪声环境下的鲁棒性。 最后,在语音解码过程中进行多重选择,提高语音识别在噪声环境下的精度。 完全消除噪声噪声目前仍然处于理论水平。
(3)模型的有效性
识别系统中的语言模型、词法模型在大词汇、连续语音识别中无法完全正确运作,需要有效结合语言学、心理学、生理学等其他学科知识。 语音识别系统在实验室演示系统向商品转型过程中,还需要解决许多具体的技术问题。
智能语音识别系统的开发方向
如今,许多用户正享受语音识别技术带来的便利,例如智能手机的语音操作。 但是,这与实现真正的人类交流相距甚远。 目前,计算机对用户的语音识别程度不高,存在交互问题。 智能语音识别系统技术还需要走很长的路,必须取得突破性的进展,才能实现更好的商业应用。 这也是未来语音识别技术的发展方向。
语音识别商业化的落地需要内容、算法等方面的协作,良好的用户体验是商务应用的第一要素,识别算法是提高用户体验的核心要素。 目前语音识别已广泛应用于智能家居、智能车载、智能呼叫机器人,将来将深入学习、生活、工作的各个环节。 许多科幻电影的场景已经进入我们的日常生活。
本文以《苏宁富信息》为原创,作者是苏宁金融研究院金融科技研究中心的沈春泽副主任