导入数据
载入资料载入资料
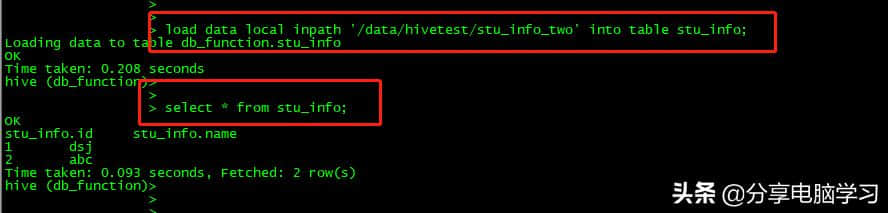
loaddatalocalinpath '/data/hive test/stu _ info _ two ' intotablestu _ info;
 加载HDFS数据,并将数据文件移动到表中的相应目录
加载HDFS数据,并将数据文件移动到表中的相应目录
首先清空truncate table stu_info数据
将数据加载到 hdfs
hdfs
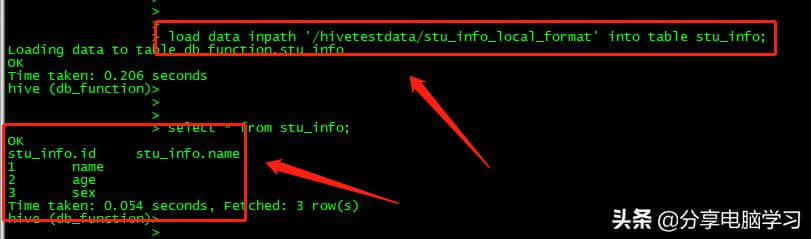
HD fsdfs-put/data/hive test/stu _ info _ local _ format/hive test data /
从 Hive看
Hive看
 然后加载数据
然后加载数据
 load data + overwrite的复盖数据将创建新的数据库以区分我们
load data + overwrite的复盖数据将创建新的数据库以区分我们
可以复盖000700000 0
0 数据
数据
local]
创建数据表
000010000[
 03、子查询as select
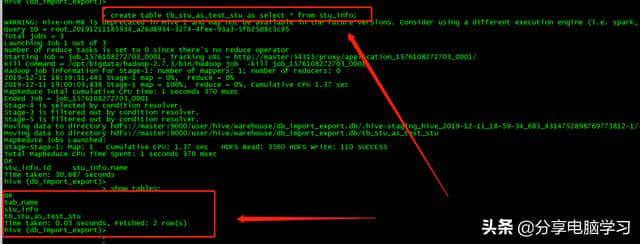
03、子查询as selectcreate table TB _ stu _ as _ test _ stuasselect * from stu _ info;
适用于保存数据查询结果
 4、insert方式
4、insert方式
插入数据的表必须存在
创建新表格
 0
0 00
00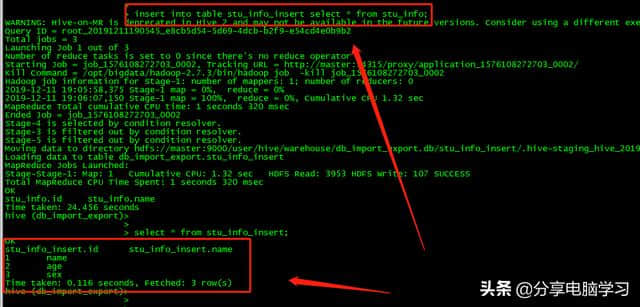 再次运行会增加数据量(添加)
再次运行会增加数据量(添加)
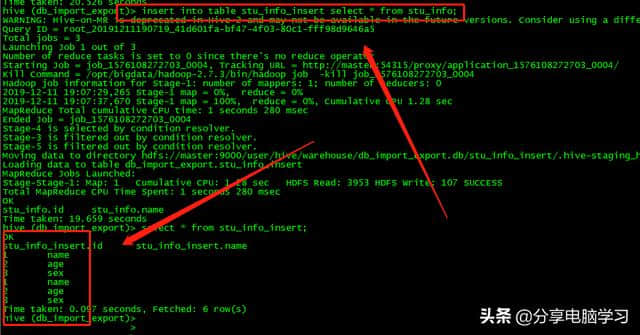 执行霸盖(原始数据改变)
执行霸盖(原始数据改变)
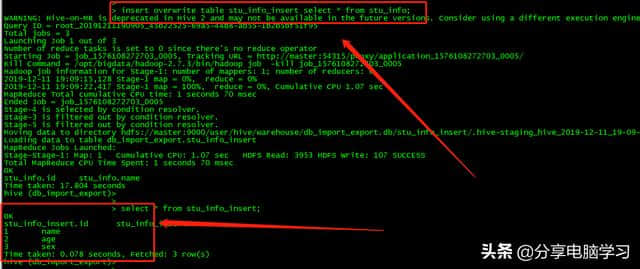 将数据插入关系数据库
将数据插入关系数据库
insert into table table_name(id,name) values(1,' test ' );
Hive也支持插入
insertintotablehive _ table _ name ( id,name )值( 1,' test ' )
注:此方法适合在数据非常小的情况下使用。 如果数据量很大,要避免此操作,show tables将检测临时表values__tmp__table__1。 这表明SQL在Hive中使用临时表进行迁移。
5、创建表时在location中指定数据文件的方式
导出数据
官方网站
显示0001700000
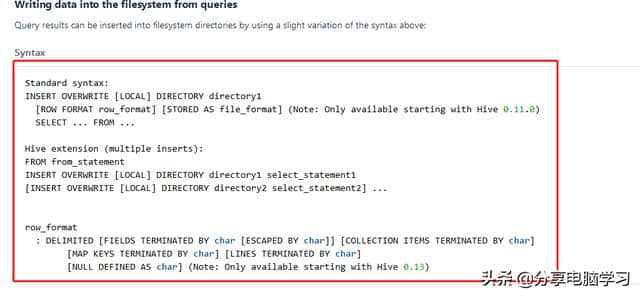 插入过程数据
插入过程数据
添加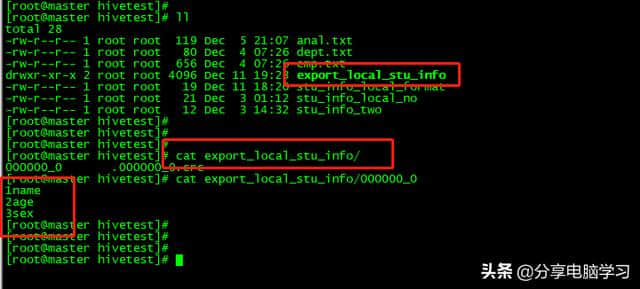 语句后,可以指定分隔符rowformatdelimitedfieldsterminatedby“”
语句后,可以指定分隔符rowformatdelimitedfieldsterminatedby“”
语句:
insertoverwritelocaldirectory '/data/hive test/export _ local _ stu _ info ' rowformatdelimitedfieldsterminatedby ' ' select * from stu _ info;
 数据中有空格
数据中有空格
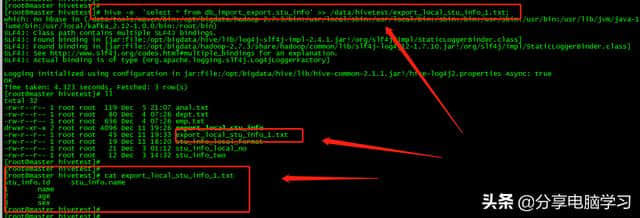
如果不使用0000230230000local,现在可以将输入导入HDFS,并使用HDFS命令下载文件
bin/hive -e或-f + > >或> hive-e ' select * from db _ import _ export.stu _ info ' > >/data/hive test/export _ local _ stu _ info _1. txt;
 可以使用sqoop等工具,使用以前的数据库
可以使用sqoop等工具,使用以前的数据库
 select * fromempwheresal > 3000;
select * fromempwheresal > 3000;
 select * from emp limit 5;
select * from emp limit 5;
 selectdistinctdeptnotfromemp;
selectdistinctdeptnotfromemp;
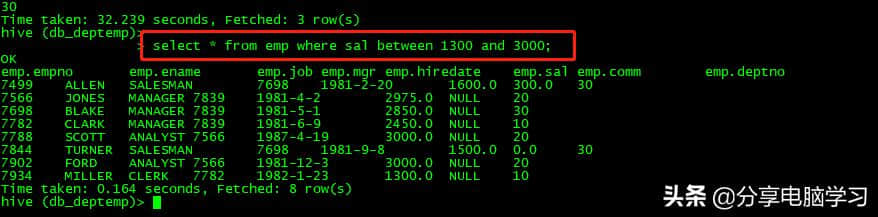
000280000 select * fromempwheresalbetween 1300和3000;
 select * fromempwheresal > = 1000 andsal
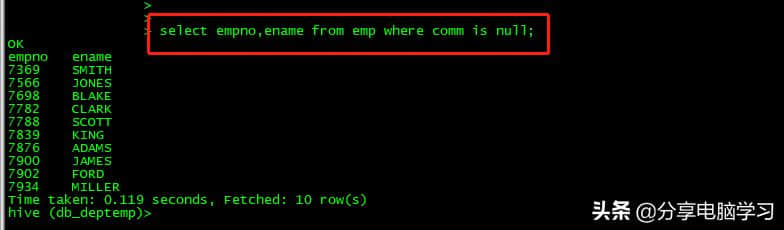
0select empno,ename from emp where comm is null;
select * fromempwheresal > = 1000 andsal
0select empno,ename from emp where comm is null;
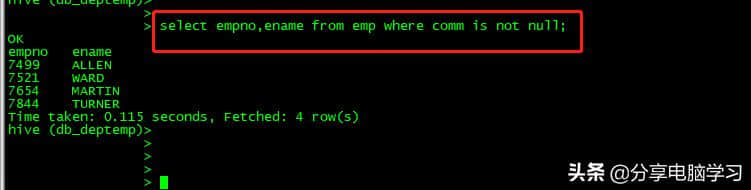
 select empno,ename from emp where comm is not null;
select empno,ename from emp where comm is not null;
 聚合函数
聚合函数
count ( )、max ( )、min ( )、sum ( )、avg ( )和group by
如果添加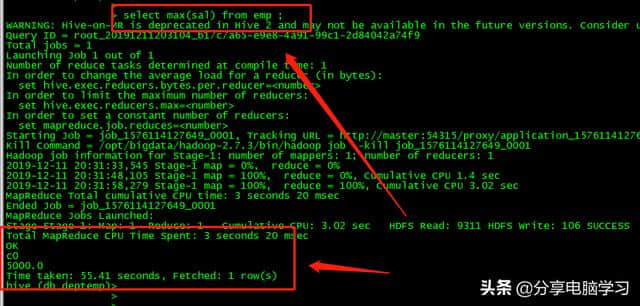 字段
字段
select deptno,max(sal) from emp;
有错误
 select中显示的字段必须包装在聚合函数中,或者包装在group by中
select中显示的字段必须包装在聚合函数中,或者包装在group by中
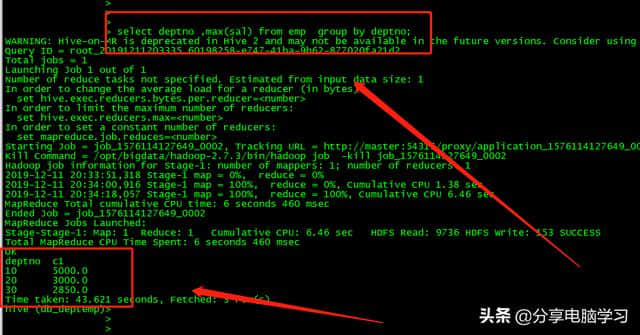
select deptno,max(sal) from emp group by deptno;
select max(deptno )、max(sal) from emp;
 00003530000join
00003530000join
left join、right join、inner join (等效)、full join (完全)
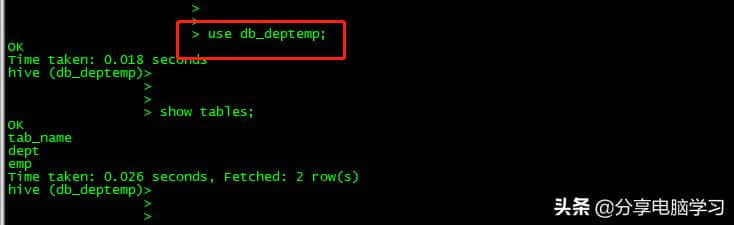
创建新库
创建两个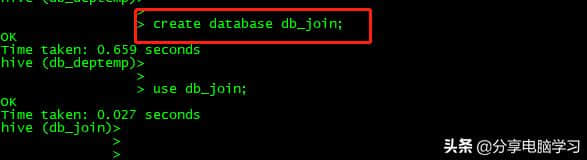 表
表
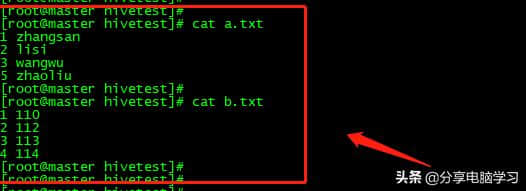
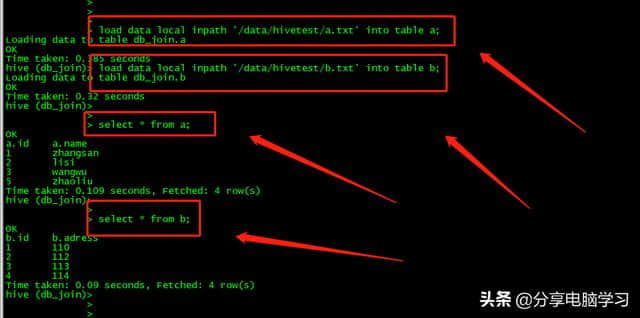
准备0003800000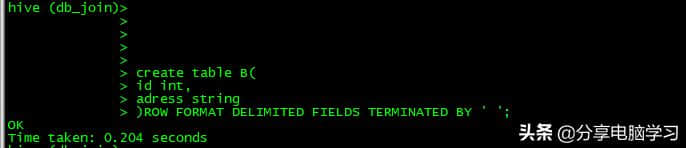 00数据
00数据
 0
0
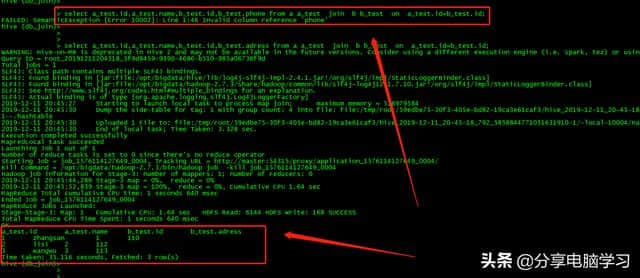
 的等值join
的等值join
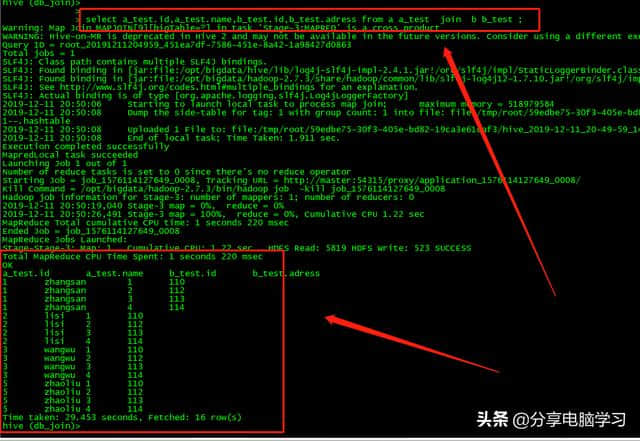
select a_test.id,a_test.name,b_test.id,b _ test.adessfroma _ testjoinb _ test ona _ test.id = b _ test.id;
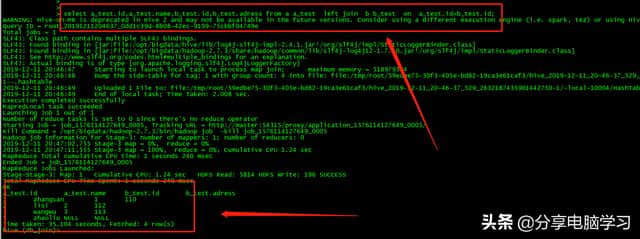
 左join,根据左表,不匹配的字段为NULL
左join,根据左表,不匹配的字段为NULL
select a_test.id,a_test.name,b_test.id,b _ test.adessfroma _ testleftjoinb _ test ona _ test.id = b _ test.id;
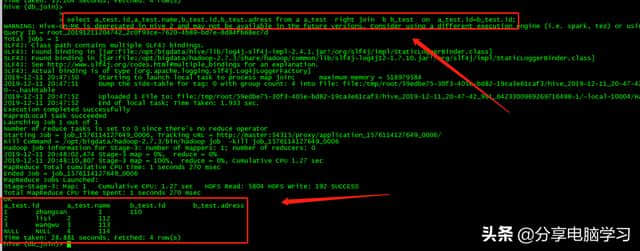
 右join,相对于右表,不匹配的字段为NULL
右join,相对于右表,不匹配的字段为NULL
select a_test.id,a_test.name,b_test.id,b _ test.adessfroma _ testrightjoinb _ test ona _ test.id = b _ test.id;
 显示所有join,所有字段,不匹配的字段为NULL
显示所有join,所有字段,不匹配的字段为NULL
select a_test.id,a_test.name,b_test.id,b _ test.adessfroma _ testfulljoinb _ test ona _ test.id = b _ test.id;
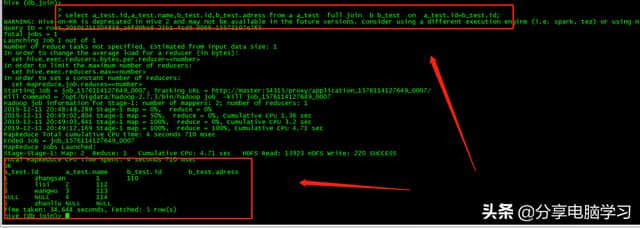 不写连接条件,将2张表作为笛卡尔积
不写连接条件,将2张表作为笛卡尔积
select a_test.id,a_test.name,b_test.id,b _ test.adessfroma _ testjoinb _ test;